Was this page helpful?
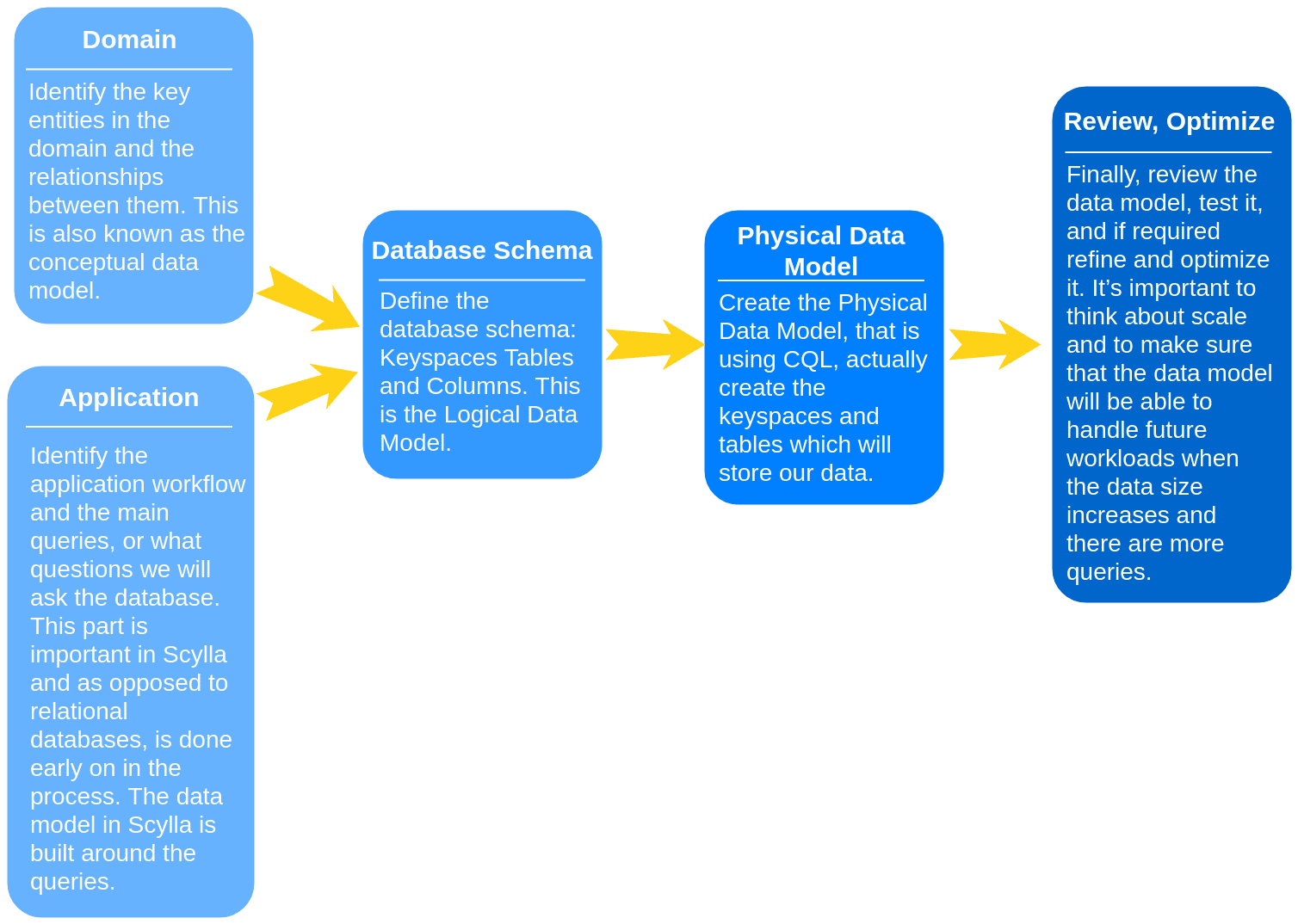
Design and Data Model¶
You can learn more about Data Modeling in ScyllaDB (and NoSQL) by taking this course on ScyllaDB University. The main goal of data modeling in ScyllaDB is to perform queries fast, even if we sometimes have to duplicate data.
Let’s build our schema around the queries we are going to run against our domain entities. When creating the data model, you need to consider both the conceptual data model and the application workflow: which queries will be performed by which users and how often.
To achieve that, we want:
Even data distribution
To minimize the number of partitions accessed in a read query.
On the other hand, our focus won’t be on avoiding data duplication or minimizing the number of writes. You’re probably familiar with the steps defined here:
Conceptual Data Model¶
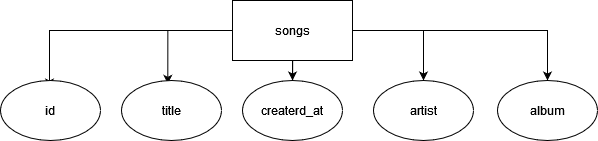
Starting with the conceptual data model, we need to identify the key entities and the relationships between them. Our application is focused in a single entity called ‘songs’. The concept is to fill with many songs as we want.
Application Workflow¶
Next, we move on to the Application Workflow. In this part, we identify the main queries or what questions we will ask the database. This part is important in ScyllaDB, and other NoSQL databases and, as opposed to relational databases is performed early on in the data modeling process. Remember that our data modeling is built around the queries.
Application Features¶
Insert a Song
List all songs
Delete a song
Stress Testing
Queries¶
Now we can detail the above queries in CQL:
Q1: Create a Keyspace
CREATE KEYSPACE prod_media_player;
Q2: Create a Table
CREATE TABLE songs (
id int,
title text,
album text,
artist text,
created_at timestamp,
updated_at timestamp,
PRIMARY KEY (id, updated_at)
);
Q3: Insert a new song
INSERT INTO prod_media_player.songs (id,title,artist,album,created_at) VALUES (?,?,?,?,?);
Q4: List all songs
SELECT * FROM songs;
Q5: Delete a specific song
DELETE FROM songs WHERE id = ?
Helpful Material¶
Some more advanced topics not covered in this guide are Collections, User-DefinedTypes (UDT), expiring data with time to live (TTL), and Counters.
To summarize, when data modeling with ScyllaDB, we have to know our data, think about our queries, pay attention to the primary key and clustering key selection, and not be afraid to duplicate data.